文章来源:赛先生微信公众号

早在2012年,电脑就已经学会识别YouTube视频中的猫;到了2014年11月,电脑甚至可以将一张照片正确地命名为“一群正在玩飞盘的年轻人”,于是人工智能研究者们欢呼着期盼“深度学习”还会带来更多成就,这套成功的算法效仿了大脑的思维方式,即仅仅通过接触发展出对于真实世界特征的敏感性。
通过运用最新的深度学习设计,科学家们已经越来越熟练地将人工神经元网络架构的计算机模型应用在图像、语音和模式识别等领域——它们都是与机器个人助理、复杂的数据分析和自动驾驶汽车相关的核心技术。可是,除了训练计算机从其他无关的数据里提取出一些显著特征外,研究人员还从未完全理解这种算法或称之为生物学习的方法为何会行得通。
有两位物理学家研究发现,某种形式的深度学习,其作用机理就如同物理学中最重要和最普遍的一种数学方法,即一种大尺度物理系统行为的计算方法,它常用于基本粒子、流体和宇宙学的计算。
这一发现由波士顿大学的潘卡吉·梅塔(Pankaj Mehta)和西北大学的大卫·施瓦布(David Schwab)共同完成。他们证明了一种叫做“重整化”(renormalization)的统计技术能够让人工神经网络实现数据分类,譬如在一个给定的视频里识别“一只猫”,无论其颜色、大小或姿势。这种统计方法原本用于物理学领域,它使得物理学家无需知道所有组分的精确状态,就可以准确地描述大尺度系统。

“这些原本只是梦里的事,他们居然用确凿的证据写成了论文,”埃默里大学(Emory University)的生物物理学家伊利亚·内蒙曼(Ilya Nemenman)如是说,“统计物理学领域里的提取相关特征,与深度学习领域里的提取相关特征,不止是说法一样,它们在本质上就是一回事。”
我们人类掌握了特殊的诀窍,能够分辨出灌木丛中的一只猫咪,人群中一张熟悉的面孔,或者我们周围被颜色、质地和声音包围的任意目标。这种生物学上的学习过程和机器的深度学习之间的强烈相似性表明,大脑也采用了某种形式的重整化来理解世界。
“从数据中提取相关的特征,也许这里面存在一种普遍的逻辑,”梅塔表示,“我认为这是一个暗示,它告诉我们或许有类似的东西存在。”
施瓦布、梅塔和其他研究者认为,在对象或语音识别的背后,物理学家的技巧和学习过程在哲学上具有相似性,上述发现使得这种观点得以正式化。重整化的过程被施瓦布形容为“把一个非常复杂的系统精炼成它的基本部分”,他说:“这也就是深度神经网络和我们的大脑同样在努力做的事。”
分层学习
十年前,深度学习似乎并未获得成功。运行程序的计算机模型往往不能识别照片里的对象或音频记录里的口头用语。
英国多伦多大学的计算机科学家杰弗里·辛顿(Geoffrey Hinton)和其他研究者,已经设计出一种在多层虚拟神经元网络上运行的程序,该神经元网络能够通过“放电”开关,发送信号至相邻的网络层。这种“深度”神经网络的设计灵感来自于人脑里视觉皮层的层级结构——该脑皮层能将光子流转换成有意义的感知。
当一个人看到猫穿过草坪时,大脑的视觉皮层会把这个场景分层解析,即每一连续层的神经元进行放电,以响应更大规模且更明显的特点。起初,如果检测到视野区域内的对比差别,即表明物体的边缘或端点位置,视网膜上的神经元就会放电并发出信号。这些信号会传输到更高一层神经元,这些神经元对边缘和其他越来越复杂部分的整合较为敏感。当信号继续向上传递时,比如一根猫胡须的视觉信号可能就匹配上了另一根胡须的信号,它们可能会和猫咪那尖耳朵的视觉信号整合,最终触发顶层神经的激活,于是对应了一只猫的概念。
辛顿早在十年前就开始尝试复制上述过程,他认为正是由于该过程的存在,发育中的婴儿大脑才越来越善于协调传感数据的明确相关性,比如学习如何把图像里猫的胡须与耳朵整合在一起,而不是背景里的花朵。辛顿试图应用一些简单的学习规则来训练深度神经网络,以达成这一目的,这些规则是二十世纪八十年代由他和神经科学家特里·谢诺沃斯基(Terry Sejnowski)提出的。当声音或图像传入深度神经网络的底层时,数据便会触发放电活动的瀑布效应。一个虚拟神经元的放电也会触发相邻层级上的互连神经元的放电,其强度取决于两个单元连接的强度。这种连接最初被随机分配了一些强度值,但是当两个神经元一同被数据激活时,辛顿和谢诺沃斯基的算法就会主动强化它们之间的连接,以增强这种连接继续成功传递信号的几率。相反,如果两个神经元之间的连接很少被用到,那么算法将会弱化该连接。随着更多图像或声音得到处理,神经元之间的连接模式会在网络里逐渐成型,就像支流系统通过各层级慢慢向上汇聚。在理论上,支流最终将汇聚到少数顶层神经元,并以声音或物体类别的形式表现出来。
问题是,在从底层网络层传到顶部类别的过程中,数据开拓路径会花太长的时间。也就是说,算法效率不够高。
在随后的2005年,辛顿和他的同事们从大脑发育的一个侧面获得灵感,从而设计了一套新的训练方案。事实上,上世纪六十年代还在剑桥大学上学的时候,辛顿就首次接触到了大脑发育这方面的知识。当时,生物学家柯林·布莱克摩尔(Colin Blakemore)通过解剖猫的大脑发现,视觉皮层是分阶段发育的,它会从视网膜开始,通过对感官数据的响应来调整其神经连接,每次一层。
为了复制大脑视觉皮层逐步发育的特征,辛顿将学习算法在他的网络中逐次每层地运行,即先训练每一层的连接,再将输出结果——相当于原始数据更为粗略的表征——作为上一层训练的输入数据,然后再对网络进行整体上的微调。这种学习过程的确变得更加高效。很快,深度学习就打破了图像和语音识别领域的准确性记录。谷歌、Facebook和微软也纷纷展开了致力于此的整体研究计划。

“在辛顿等研究者的手中,这些深度神经网络成为了最好的分类器,”耶路撒冷希伯来大学的计算神经科学家兼计算科学家纳夫塔利·蒂希比(Naftali Tishby)评论说,“不过,这一点也同样困扰着机器学习方面的理论家,因为他们还不明白为什么这种网络如此有效。”
深度学习之所以在很大程度上有效是因为大脑也是如此运作的。这种类比还远不够完善;大脑皮质比人工神经网络更加复杂,其内部网络不停运行着未知的算法。在辛顿的突破出现之后的几年里,深度学习由自身出发,向着各个方向形成了分支,它运用各种在生物学上难以置信的算法,解决了许多学习任务上的难题。现如今,辛顿在多伦多大学和谷歌之间巡回工作,他认为机器学习和生物学习之间存在一个关键原则:“学习的时候,你总是从简单的特征开始,然后基于那些你所学的去理解更复杂的特征,这是一个分阶段的发展过程。”
从夸克到桌子
2010年,当时还在普林斯顿大学担任生物物理学博士后研究员的施瓦布,专门乘坐火车到纽约市去听辛顿介绍深度学习的演讲。辛顿提出的逐层训练过程让他很快想起在物理学领域被广泛使用的一种技术,“一种体现何谓物理学的技术”,施瓦布说。
回到普林斯顿以后,施瓦布打电话给梅塔,问他是否觉得深度学习听起来很像重整化。早在几年之前,两人就通过一个暑期研究项目成了朋友兼合作者,他们经常相互探讨“疯狂的想法”。梅塔并不觉得重整化类比特别疯狂,于是两人开始着手研究这个直觉是否正确。“我们经常在深夜互相打电话,然后就这么一直聊下去,”梅塔说。“我们有些陷入痴迷了。”
重整化是一种从微观到宏观的描述物理学系统的系统化方法,它紧扣影响其大尺度行为的要素,并对其余要素进行平均化。令物理学家感到庆幸的是,大多数最微观的细节都是无关紧要的;比如描述一张桌子,我们不需要知道在亚原子层面的所有夸克之间的相互作用。但是,需要一套复杂精巧的近似方案向上跨过距离尺度,一路上放大相关的细节,同时模糊无关的细节。
最终的突破出现在蒙特利尔爵士音乐节上,当时梅塔和施瓦布正在喝酒。他们决定把重点放在一个被称为变分或“块自旋”(block-spin)的重整化程序上,这个重整化方案是统计物理学家利奥·卡丹诺夫(Leo Kadanoff)在1966年发明的。块自旋方法包括将一个系统内的组分组合成更大的区块,每次重组会取系统中的平均组件。该方法可以很好地描述类分形对象,即在所有尺度或不同分辨等级下,看起来都有相似形态的对象。卡丹诺夫理论里的典型例子便是二维伊辛模型(Ising model),它是一种自旋晶格,或被视为指向上或指向下的微磁极。卡丹诺夫指出,通过从依据自旋状态来描述转变为依据自旋块来描绘,人们可以很容易地对晶格进行放大。
施瓦布和梅塔希望在深度学习的数据层次表征里应用这个方法,他们翻来覆去地研究了卡丹诺夫的那篇老论文以及辛顿及其同事们在2006年发表的两篇详细探讨首个深度学习协议的高引用论文。最终,他们找到了如何把一种程序的数学表达映射到另一个程序中去,进而证明了这两种对世界特征总结的机制本质上是相同的。
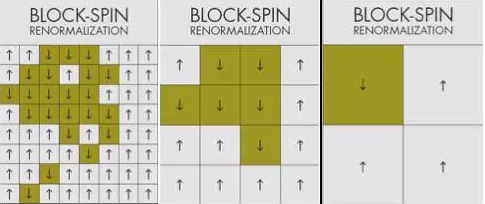
为了说明两者的对等性,施瓦布和梅塔训练了一个包含20000例伊辛模型晶格的四层神经网络。从下一层的神经网络到上一层,神经元自发地表征为更大片的自旋区域,并用卡丹诺夫的方法归纳数据。“它从应当进行区域重整化的样本开始学习,”梅塔说。“你不用手把手教它,它自己就能学习,这令我们感到震惊。”
相比类似分形的磁铁晶格,当深度神经网络遇到猫咪的照片时,它可能会使用更多样更灵活的重整化方式。但研究人员推测,它同样会先从像素尺度逐层移动到宠物照片的尺度,剔除或整合数据里与猫咪相关的元素。
归纳世界
研究人员希望统计物理学和深度学习领域之间的交叉结合会在这两个领域产生新的进展,但施瓦布认为,“在任一方向上产生杀手级的应用程序”依然言之过早。
由于深度学习会根据手头的数据进行自我调整,因此研究者希望它能够用于评估对于传统重整化方案而言太过复杂的系统行为,如细胞或复杂蛋白质的聚集过程。这些生物系统往往缺乏对称性,看起来毫无分形特征。对于这些系统,“我们在统计物理学研究中发明出的机械化步骤没有一个能用得上,”内蒙曼说,“但我们仍然知道,既然我们自己的大脑能认知现实世界,那么肯定存在某种粗粒度的描述方法。如果现实世界是不可归纳的,那么这样的描述方法就不会存在。”
深度学习也让我们有希望从理论上去更好地理解人类认知。宾夕法尼亚大学的神经科学家维贾伊·巴拉萨布拉曼尼恩(Vijay Balasubramanian)说,他和其它跨领域专家很早就意识到重整化和人类感知之间的概念相似性。“施瓦布和梅塔的论文成果可能会给我们带来精确类比的工具。”巴拉萨布拉曼尼恩说。
例如,这个发现似乎支持了一种新兴的假设:部分大脑的工作处于一个“临界点”上,其中每一个神经元都可能影响整个网络。来自加州拉荷亚萨尔克生物研究所(Salk Institutefor Biological Studies)的谢诺沃斯基教授解释到,在物理学中,重整化其实是把一个物理系统的临界点用数学化表示,“重整化和大脑可能相关的唯一途径在于后者是否处于临界点。”
这项研究里还可能包含更深层次的信息。蒂希比就把它看作是重整化的、深度学习和生物学习其实都可以被信息论中的一个理论所囊括。所有这些技术的目的都是为了减少数据冗余,一步一步地将信息压缩到它的本质,以至于在最后的表征中,没有任何字节是彼此相关的。例如,猫咪有许多表达其存在的方式,只是深度神经网络将它们不同的相关性整合在一起,并将之压缩成单个虚拟神经元的形式。“神经网络所做的正是压缩信息,”蒂希比说,“而这也正是深度学习的瓶颈所在。”
通过将逐层剥离的数学步骤把信息拆分至最简化形式,“这篇论文的确打开了一扇大门,让我们通向非常令人兴奋的领域。”蒂希比说。